
Introduction: a quick scene, a number, a pressing question
I was in a plant last month watching operators chase a leaky roll — the kind of small chaos that stretches into hours. The plant had been running the same setup for seven years, and their latest wet wipes production line promotions barely moved the needle on sales or downtime. Industry reports say average line OEE can sit 10–20% below target in such factories; so I asked myself: how many warning signs are you willing to ignore? (I think we both know the answer isn’t “all of them”). This piece maps the clues I’ve seen, backed by simple data and my own shop-floor days, and leads into practical fixes you can test tomorrow.
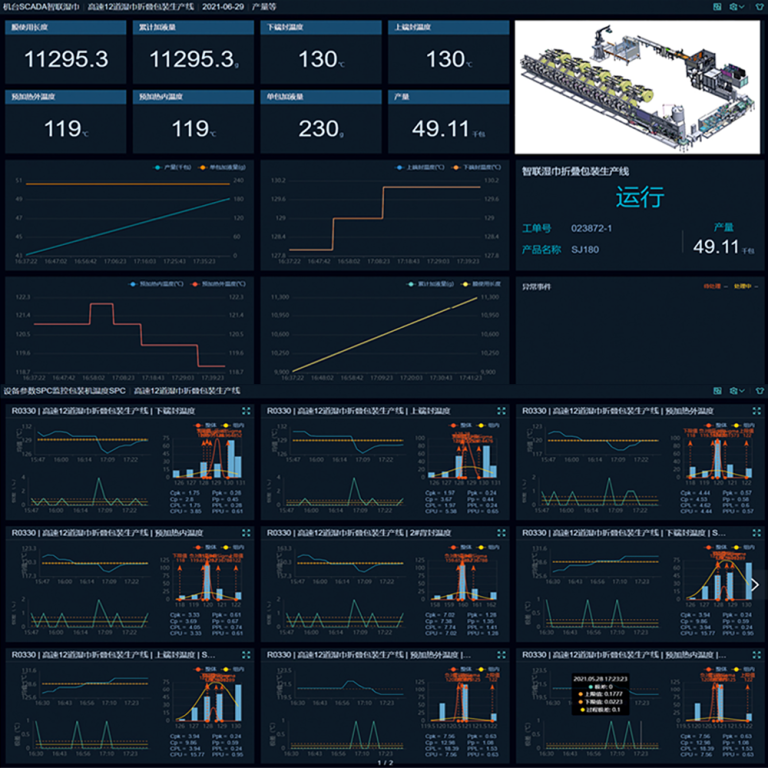
Part 2 — What’s really wrong with the old approach (technical breakdown)
Let’s be blunt: old systems were built for a different pace. The automatic wet wipe machine era demands tighter control, and many legacy lines lack modern feedback paths. I’ve tracked repeated losses to poor tension control, weak servo motor response, and PLC logic gaps. Those are not abstract terms — they’re the things that stop a roll, ruin a batch, and force overtime. Look, it’s simpler than you think: if your line can’t report real-time machine states to a SCADA/MES layer, you’re flying blind. Add in aging power converters and outdated HMI screens, and you get frequent manual fixes. That costs time and morale.
Why do these failures keep happening?
Most teams patch symptoms instead of changing architecture. Without edge computing nodes or integrated humidity sensors the system can’t adapt to shifts in raw-material moisture or speed. I’ve seen teams retool drives and still get web breaks because they ignored root-cause noise in the PLC ladder logic. We patch. The problem returns. — funny how that works, right?

Part 3 — New principles for the next line: a forward-looking playbook
What new rules should guide upgrades? Start with data-first design. An automatic wet wipe machine paired with SCADA and MES gives you traceability, predictive alerts, and faster changeovers. I recommend modular control, with local PLCs handling motion (servo motor and tension control) and edge computing nodes aggregating KPIs. That split keeps cycles fast and analytics honest. Short sentence: you get more uptime. Longer one: you also reduce waste and speed product launches — measurable wins that matter to procurement and marketing.
What’s Next: how to judge a good upgrade
Compare options by three simple metrics: changeover time, mean time to repair, and first-pass yield. I use those because they tie directly to cost, not just features. If a supplier promises “smart,” ask for real cases: show me downtime numbers before and after; show me raw data. Small teams can pilot one packer or folder. Scale only when the KPIs prove out. I’ll add this — don’t forget human factors. Training and clear visual dashboards keep operators confident. — and that is often the real difference between a system that collects data and one that drives decisions.
To close, I’ll be candid: upgrades are worth the headaches when they cut unseen losses and free people to do higher-value work. Evaluate vendors by results, not buzzwords; test in small steps; and demand measurable improvements. If you want a practical partner with field-proven systems, check out ZLINK. I’ve seen their implementations move lines from reactive to proactive — and that’s the future I want to build with teams like yours.